Designing a High Performance Rust Threadpool for Kafka with mTLS¶
Update 2022-09-23¶
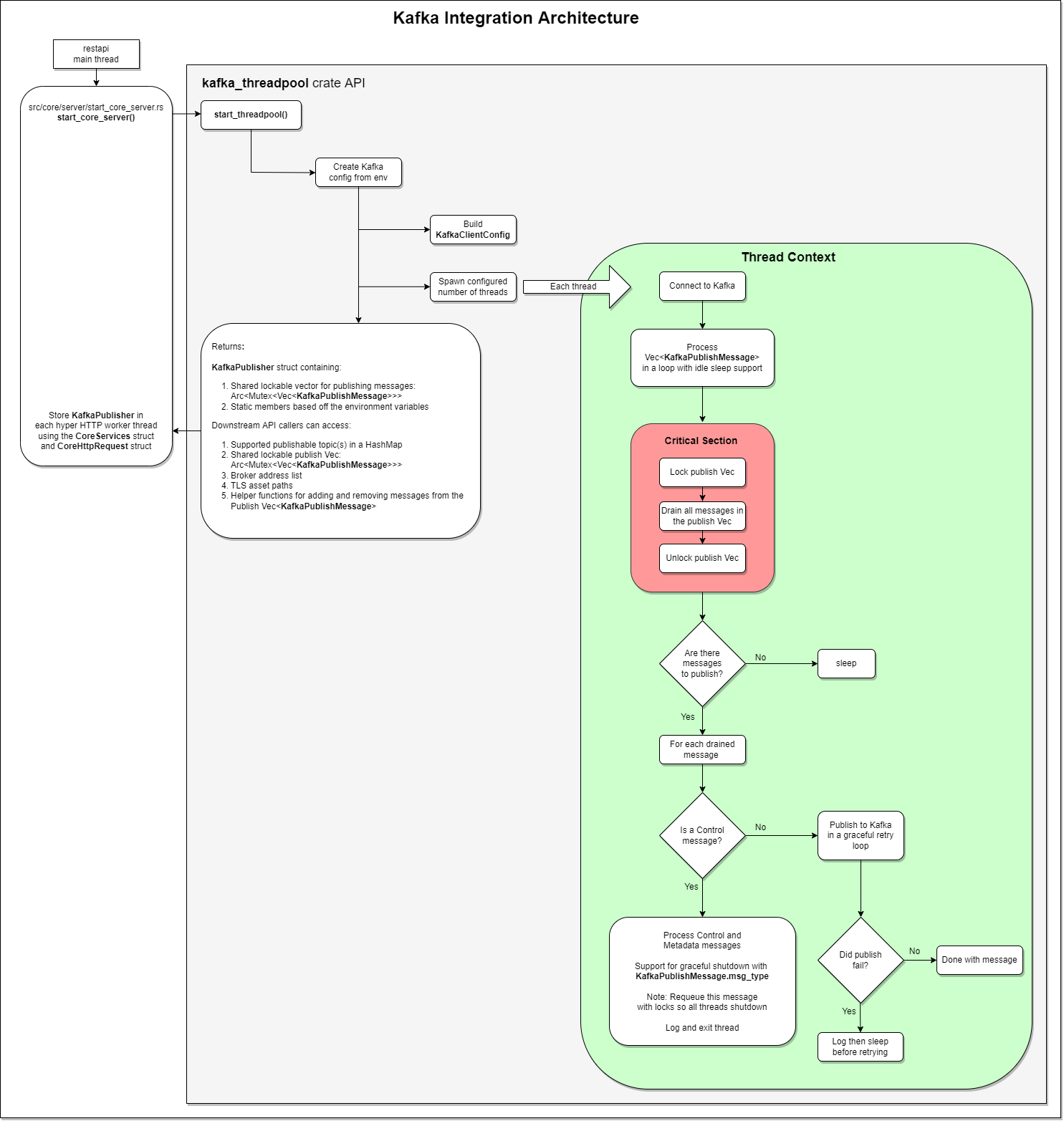
This v1 kafka threadpool design works and is already available in the restapi and rust-kafka-threadpool repositories with docs:
Lessons Learned and Postmortem¶
How long did it take to integrate this new kafka threadpool?¶
After reviewing the rust-kafka-threadpool commit history, it took about 24-32 hours to build a new, functional rust kafka threadpool crate from this blog’s design and integrate into an existing crate with documentation.
Was it worth it?¶
Rust’s Arc and Mutex types made it easy to abstract and reduce critical section impacts with the new kafka-threadpool crate.
As mentioned in the django notes below, the more I program in multiple languages the more I find myself continuing to use this “static configuration drives implementation” approach to make my architecture more flexible (see the django settings.py comments in the Integration Task 1 - CoreConfig struct section).
The last 6-8 hours were spent hardening a tool for generating mtls-ready assets for encryption in transit using cloudflare’s cfssl tool and making the new tls assets deployable into kubernetes. I plan on creating a new github repo to share this new “secure anything” approach, and you can find the proof of concept already in the restapi ./tls directory.
What are the tradeoffs?¶
Like most engineering tasks, I think the tradeoffs are around making it “easy to use” while providing “enough flexibility” that I can pivot if I hit a technical roadblock with my design.
Rust is an emerging ecosystem when it comes to crate version upgrades. I lost a few minutes learning + upgrading to the latest jsonwebtoken validation which required changing the restapi user auth JWT validation. I was honestly dreading updating some of the core crates that provide a lot of the “batteries included” functionality (hyper, tokio, serde), but thankfully none of those new versions broke anything. I am really not looking forward to refactoring how I use those crates in the future for some new version upgrade. Rust reminds me a lot of the early python 3 days where things were moving quickly and version upgrades could always bring new and exciting changes with an unexpectedly large blast radius.
Background¶
Today I want to design a configurable threadpool for kafka that will work for my restapi hyper server project using client mTLS for authentication. The last blog post outlined how to host a 3-node kafka cluster that enforces mtls for client for connections with the strimzi operator. Once the kafka cluster was working, I built a proof of concept rust mtls client that works with kafka from environment variables. With the proof of concept wrapped up, I can start designing the threadpool.
Getting Started¶
Building a threadpool is pretty common in systems engineering, and each time I write one of these I get to see how new languages handle something difficult like concurrency and mutual exclusion. With rust I think it will be much easier to design a multi-threaded pool that is contained within a new rust library (a crate I’m tentatively calling by the very creative name: kafka_threadpool). Fingers crossed! Let’s find out how much of a time sink this ends up being.
For learning about how I plan to implement mutual exclusion within concurrent rust threads please check out:
Proposed Integration Points for the Restapi Hyper Server¶
Before writing any code I think it’s important to look at where, what and how I want to integrate and reuse something as nice-to-have as a generic threadpool architecture.
Task 1 - CoreConfig struct¶
I haven’t written an architecture blog post on the restapi, because it really reminds me of my old python django repos at this point. I wrote the server to imitate some of the niceness django uses like the settings.py Common(Configuration) object that provides connectivity to remote endpoints and services (like redis in the settings.py ). This same server configuration object is represented in the restapi in the CoreConfig struct. This will be the first integration point for the threadpool with the ability for the server to detect connectivity endpoints via environment varibles prefixed with a KAFKA_* name. Environment variables for tls assets will be paths to files like the proof of concept pub/sub examples.
Task 2 - start_core_server() function¶
Upstream Considerations¶
After adding connectivity members to the CoreConfig struct, the next integration point is during the hyper server’s helper startup function: start_core_server(). I enjoyed working with the bb8’s postgres threadpool for database encryption in transit, and wrapped its integration within the get_db_pool() function (Please refer to the official bb8 hyper.rs example for additional customization details).
Design implications for startup:
Note
When kafka is enabled, the kafka_threadpool will connect and start up before the server responds to any client HTTP requests (just like the tls certification checks and bb8 postgres threadpool).
Downstream Considerations - Hyper Worker Access Model¶
By adding the new kafka_threadpool into the server during the start_core_server() function, I can plan to clone the publishing work vec within an Arc<Mutex<Vec<KafkaPublishMessage>> for shared critical section access across all the hyper server threads responding to HTTP traffic. This design choice means the new kafka_threadpool crate functionality will be accessed by the hyper worker threads as a new variable like the: db_pool argument for the bb8 postgres client threadpool (hopefully with the creative name of kafka_pool). Here’s how the bb8 threadpool is passed into the create_user function with create_user rust docs as a reference for future users looking into server integrations.
Task 3 - CoreServices struct¶
The kafka_threadpool KafkaPublisher object needs to be added to the CoreServices struct. This object is created and passed to all hyper worker threads before calling tokio::spawn.
Note
The CoreServices struct is created by the main restapi thread and passed to all tokio-spawned hyper HTTP worker threads.
Warning
As long as the proposed KafkaPublisher struct’s member fields support the rust Clone trait, then this integration will mimic the current bb8 postgres db_pool member on assignment.
Task 4 - CoreHttpRequest struct¶
Similar to the CoreServices integration task, the CoreHttpRequest struct needs to support the new kafka_threadpool KafkaPublisher object when the CoreHttpRequest object is passed to the handle_request(CoreHttpRequest) function to ensure all HTTP requests can publish to kafka.
Note
The CoreHttpRequest struct is created each time an individual hyper worker thread receives an HTTP request. The main thread does not use the CoreHttpRequest struct - only the HTTP worker threads processing HTTP traffic.
Requirements¶
By outlining the initial integration points, I can propose some more detailed requirements and start thinking through code changes before I write anything.
Remote connectivity and client configuration are defined by environment variables (paths for tls assets, number of publishing worker threads, retry sleep counters, logging level, etc).
The
kafka_threadpoolcrate should provide a wrapper struct like bb8’s Pool object for easier future integrations.Kafka can be turned off and on with an environment variable.
Startup logs: connectivity endpoint(s) and tls asset paths.
Startup should failed if the kafka cluster is enabled and not working, and there should be failure log(s) showing as much as possible of the error/reason.
Processing logs clearly show failures and retries with endpoints and tls assets (maybe even a json payload if it’s not something tagged a
sensitive message typeenum value).Clients should be able to easily create and debug all publishable
KafkaPublishMessageobjects.Speed. I want to benchmark kafka in kubernetes under a rest service using rust. Minimum latency impact on hyper HTTP workers as they share access to the publishing Vec:
Arc<Mutex<Vec<KafkaPublishMessage>>.Graceful client shutdown to prevent message loss.
Retries blocking
kafka_threadpoolpublishing due to the current assumption #1. Failures in production should gracefully retry without blocking the hyper HTTP worker threads. As long as the number of messages does not overflow the host’s memory with the size of thepublishing vec, then this requirement should pass. I expect initially the publishing failures will be due to something new and exciting I did incorrectly with the strimzi kafka cluster configuration, and I would still want to see the message tests publishing actual messages instead of having to fire off more retests due to something like a message getting lost or even worse a message drop event.Reuse. I want to reuse the
kafka_threadpoolstructs and API with future rust consuming client(s).I want to document how to extend the restapi for future threadpool or remote service endpoint integrations.
Proposed Architecture v1¶
With the requirements in mind here’s my v1 reference architecture: